Related paper: Hi5 ✋: 2D Hand Pose Estimation with Zero Human Annotation
Introduction
Hi5 is a synthetic hand dataset with pixel-perfect coordinates, created in a game engine, designed specifically for accurate pose estimation. This project was my very first undertaking when I joined the Rochester Human-Computer Interaction Lab. At the time, the team was developing a Parkinson's symptom screening tool website to make neurological assessments more accessible to the elderly and economically disadvantaged, providing a platform to guide them towards the right resources. One of the key tasks in the screening process was a motor test, requiring users to perform specific hand movements, such as finger tapping, to detect potential hand tremors. Given that older individuals often struggle with technology, their hands might go off-webcam or be in low-light conditions, causing Google's Mediapipe model for hand pose estimation to fail. This challenge led to the creation of Hi5, aiming to overcome these limitations and ensure robust hand pose tracking.
Challenges and Motivation
The process of crafting an accurate and versatile dataset for AI modeling is often confronted with significant time and financial constraints. Traditional methods typically involve possessing substantial budgets to employ human labelers who manually identify and annotate each point of interest. During our research, we also observed a lack of diversity in many existing datasets, causing models trained on them to perform better on certain races. This added an extra dimension to our process, making the Hi5 project a breakthrough by leveraging technology to generate a synthetic dataset that bypasses these limitations and ensures greater inclusivity.
Methodology
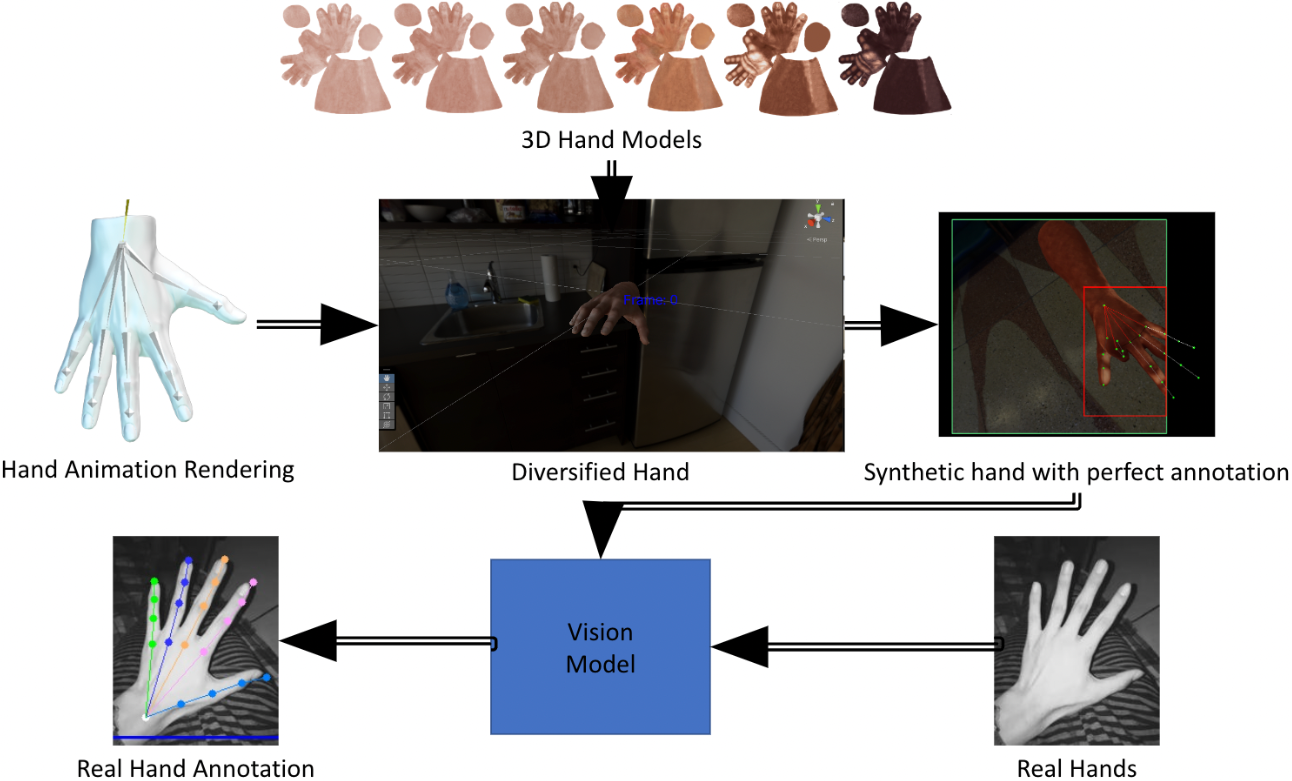
Our methodology initially involved using a Leap Motion controller to record hand animations, which were later retextured automatically during the data creation process. However, we soon encountered limitations in the Leap Motion's ability to capture more complex poses. To address this, I manually animated the hand to perform over 40 poses, selected from Facebook's paper on hand pose estimation. Additionally, we crafted 12 different 3D hand models, factoring in gender and six significant skin tones based on ITA values. This effort significantly increased the inclusivity and representativeness of the dataset and the robustness of the models we trained.
Data Augmentation
We found that heavily augmenting the data made the model more robust, especially in low-light conditions. All the hands originated from 3D left-hand meshes, but we horizontally flipped half of the images to create "right" hands. Additionally, the randomized nature of the camera angles, zoom levels, and cropping during data augmentation allowed us to collect perfect pose estimations even for synthetic hand images with missing fingers outside the frame. The main augmentations can be split into color space operations and geometrical operations. Geometric transformations involve altering the spatial arrangement of pixels within an image, such as downscale-upscale resampling, scaling, stretching, and translation, which improve the model's ability to generalize across various spatial configurations. Color space operations modify the color attributes of an image, including adjusting brightness, color balance, contrast, equalizing the histogram, and applying color filters. These changes help the model become robust against variations in lighting and color distribution.
Data Collection and Processing
The 3D models were placed against 100+ HDRI backdrops, with variations in exposure levels to capture diverse lighting conditions. A camera within the Unity scene, positioned at random angles and distances, captured these setups. The Unity game engine collected data as a CSV file. The Unity game engine collected data as a CSV file, which we then augmented with various color space and geometrical operations, resulting in a new CSV file containing all the augmentation information. In the end, the entire dataframe was converted to COCO JSON format, a widely used format for object detection that includes detailed annotations for each image. While creating this comprehensive pipeline, I was responsible for conducting a literature survey to determine how to categorize skin tones, selecting appropriate data augmentation methods, collecting and managing the data as a CSV, and developing a data-in data-out pipeline that ultimately outputs the COCO JSON format compatible with our HRNet architecture.
Results
The culmination of these efforts resulted in Hi5 - an unlimited generator of unique hand images, capable of creating approximately 500,000 images in 24 hours. A task generally considered expensive and time-consuming became both cost-effective and efficient, with the cost reduced to mere electricity charges for running the system and the process speed increased to just a few hours.
Hand Detection and Pose Estimation
To find the hand bounding boxes in the captured footage, we used hand detection models based on the University of Michigan's Fouhey Lab's '100 days of hand' dataset. I trained the YOLOv7 model for hand detection, which identified the bounding boxes, allowing us to zoom into those regions. With the pipeline in place, HRNet's architecture was trained on this synthetic dataset. Subsequently, the emergence of the VitPose paper led us to train an improved model using VitPose, culminating in achieving a Percentage of Correct Keypoints (PCK) of 96.08%.
Conclusion and Future Directions
Months of iterative refining of our dataset and pipeline led to successful tracking of fingers, even when hands were partially leaving the frame. However, we also identified limitations that opened new avenues for future exploration. While making a direct comparison to the current state-of-the-art was challenging due to the domain gap between 'in-the-wild' environments and synthetic environments, we confirmed synthetic data's efficacy. The Hi5 project highlights the strides made in advancing hand pose estimation research, delivering a foundation for using synthetic data in niches where data scarcity is a prominent concern.